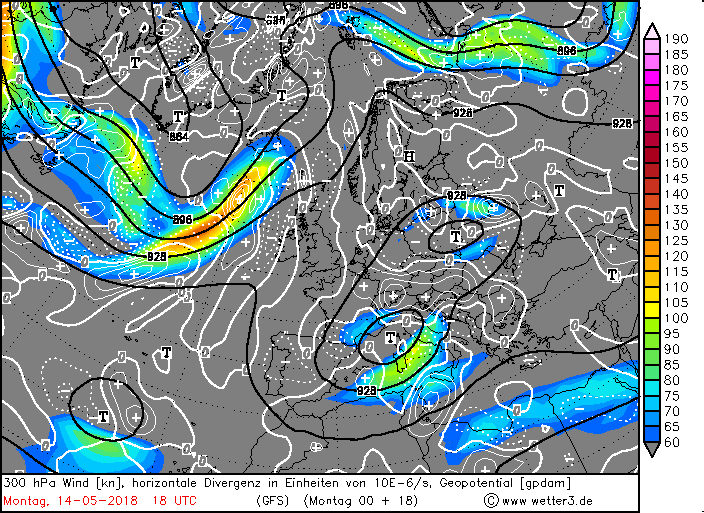
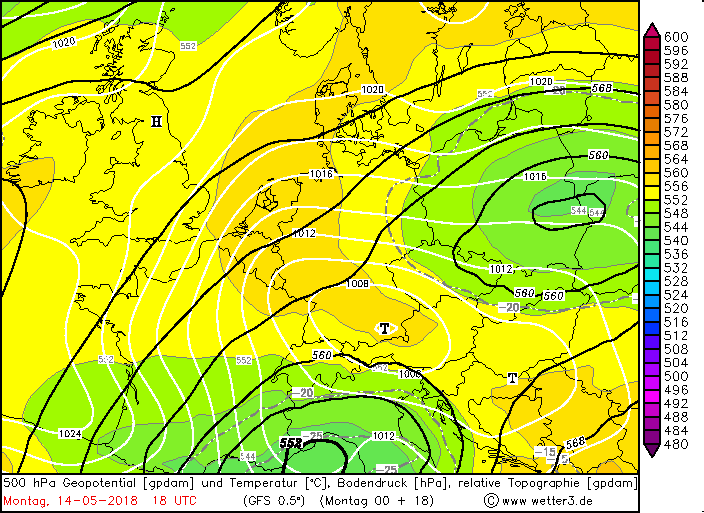
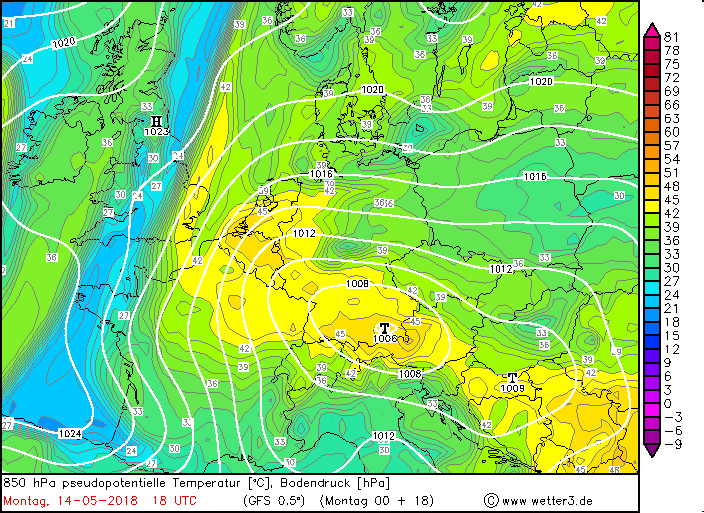
@ Matt: Modellverifikation des Niederschlags ist eine recht schwierige Sache, besonders wenn's um den Vergleich verschiedener Klassen von Modellen geht (global non-hydrostatic vs high Resolution convection permitting). Am schönsten wäre, man hätte eine langfristige Verifikation nach der SAL-Methode von Heini Wernli (Structure-Amplitude-Location), das haben wir leider nicht. Habe grad auf die Schnelle auch keine Verifikation gegenüber Radar gefunden, aber ein paar schöne Plots der Stations-basierten Verifikation (Datengrundlage SYNOP) kann ich liefern, voilà.
Dargestellt ist nachfolgend der MeanError (ME) oben und der MeanAbsoluteError (MAE) unten der 12h-Niederschlagssumme, zuerst für die aktuellen vergangenen 7 Tage, für Leadtimes +15 bis +24 Stunden, unsere MeteoSchweiz Standardmodelle IFS HRES, COSMO-7, COSMO-1 und COSMO-E (ctrl und median), die Verifikationsmasse als Funktion der Tageszeit um mögliche systematische Abhängigkeiten vom diurnal cycle festzustellen:
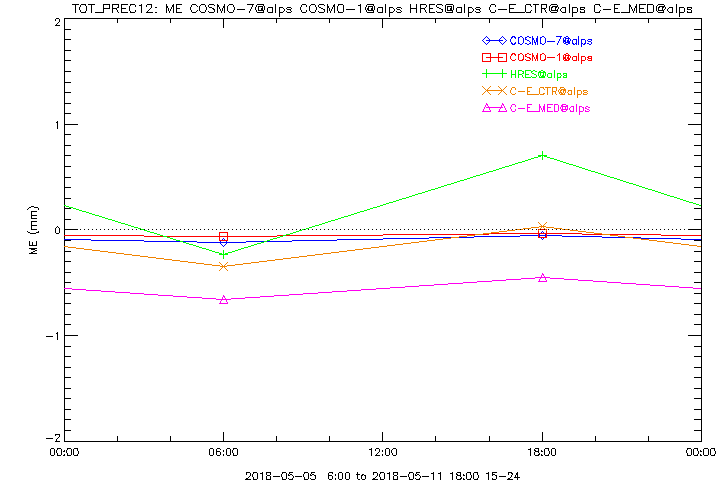
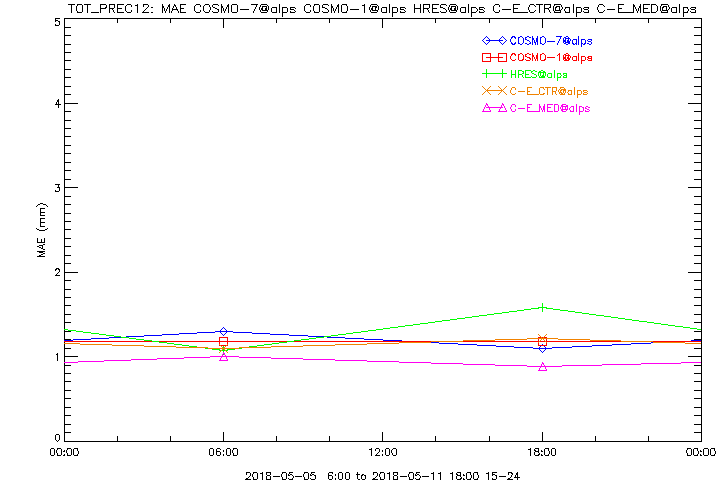
Man erkennt, dass COSMO-1 und -7 im Mittel der geringsten Fehler haben, wobei man im Hinterkopf haben muss, dass sich über- und unterschätzte Stationen in diesem Score ausgleichen. IFS HRES weist eine Abhängigkeit von der Tageszeit auf und überschätzt tagsüber die Niederschläge im Mittel, was zumindest teilweise mit der parametrisierten Konvektion und der gröberen Auflösung erklärt werden kann.
Im mittleren absoluten Fehler zeigt sich ein anderes Bild, hier schneidet der COSMO-E Median am besten ab. Das heisst, ungeachtet des Vorzeichens (Unter-/Überschätzung ist Wurst) kommt man mit den COSMO-E Medianprognosen dem gemessenen Niederschlag am Nächsten. Dabei gilt es zu bedenken, dass der Median (i.e. der Zentralwert einer Verteilung) die Extrema (d.h. einzelne krasse Members) aussen vor lässt und meist ein stark geglättetes Niederschlagsfeld und keine, oder nur stark eingeschränkt, kleinskalige physikalische Strukturen zeigt, da es sich um eine rein statistische Grösse handelt. IFS HRES überschätzt auch hier die Niederschläge tagsüber.
Hier dieselben Plots für den vergangenen Sommer 2017, JJA. Die Grundaussagen sind im Wesentlichen dieselben.
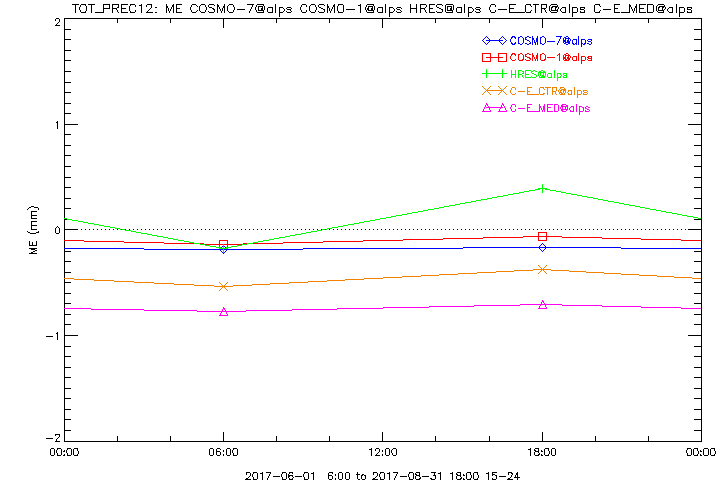
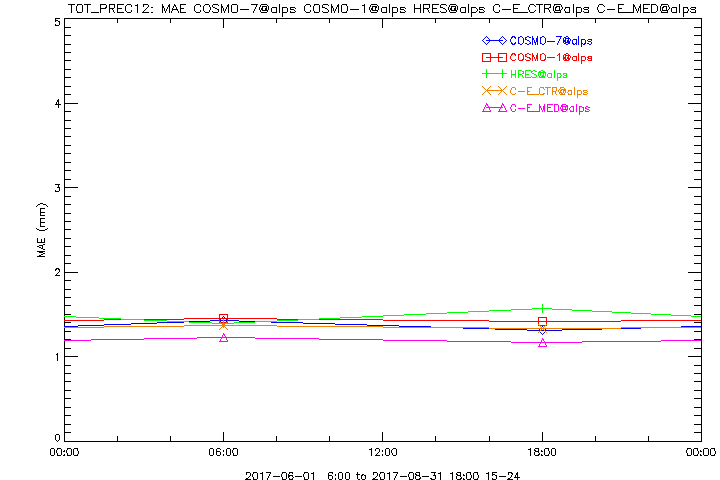
Nun könnte man sagen, dieselben Plots hätte man gerne flächendeckend ausgewertet gegen Radar- oder kombinierte Daten (CombiPrecip ist unser Paradeprodukt, welches die beiden Sensortypen optimal kombiniert). Ausserdem stellt sich zumindest im Sommerhalbjahr die Frage, ob die geringen Niederschlagsmengen überhaupt relevant sind, oder ob man sich auf die Grössenordnungen >5mm o. ä. fokussieren sollte. Kürzere Akkumulationszeiten wären auch spannend. Stratifizierung nach verschiedenen Wetterlagen, oder nach Monaten, oder unterteilt in einzelne Perioden mit denselben Modellversionen, und und und ... Am Schluss hat man 1000 Plots und weiss gar nicht mehr, was eigentlich abgeht

Darum habe ich oben erwähnt, dass Niederschlagsverifikation (oder Verifikation allgemein) eine schwierige Sache ist, wenn man einmal beginnt, genau darüber nachzudenken. Am Anfang muss man sich die Frage stellen: WAS WILL ICH SEHEN, und WELCHE ART DER VERIFIKATION GIBT MIR EINE ANTWORT AUF DIESE FRAGE?
Diese stark gemittelten Plots oben helfen unseren Modellierern insbesondere dabei, neue Modellversionen mit neuen Features zu testen und auf Fortschritt zur jeweils aktuellen Version zu prüfen. Parallel dazu versuchen wir täglich, einen Austausch zwischen den Modellierern und den Forecastern zu machen. Die Modellierer, welche oft einen sehr technischen fundamental-physikalischen Blickwinkel auf das Modell und die Realität haben, sind froh über unseren Input aus der Nutzer-Perspektive. Umgekehrt profitieren unsere Forecaster vom Dialog mit den Modellierern, um die Schwierigkeiten der numerischen Behandlung des Wetters besser zu verstehen und das Modell so situativ angepasst optimal nutzen zu können. Hört sich gut an, oder?

In der Praxis ist das letztendlich für beide "Typen" dann doch wieder nicht so einfach, denn der Forecaster arbeitet subjektiv unter täglichem kurzfristigem Zeit- und Entscheidungsdruck mit limitierten Mitteln, er ist dabei zwangsläufig mehr oder weniger ungenau und er neigt dazu, aktuell erlebte Einzelfälle stark in die Modellbeurteilung einfliessen zu lassen (was einmal gut, ein anderes Mal schlecht sein kann). Verifikationsresultate der oben dargestellten Art in diese Arbeit einfliessen zu lassen, ist dabei gar nicht so einfach. Der Modellierer wiederum schraubt und bastelt an seinem Code rum und versucht an allen Ecken und Ende kleine physikalische und numerische Dinge zu verbessern, damit das Ganze besser funktioniert. Er schaut nur wenig auf das aktuelle Wetter, und ob "sein" Modell dieses im Griff hat. Er testet an Einzelfällen, seine Optimierungen müssen aber am Schluss über eine längere Vorhersageperiode (Wochen-Monate) einen positiven Effekt im Gesamtsystem bringen, sonst gehen sie nicht in die nächste Modellversion ein (so kann bspw. eine Modelländerung einen positiven Effekt haben auf die 2m-Temperatur, aber einen negativen auf den Wind, will man das ...?). Daher betrachtet er am Schluss immer lange Zeiträume und grosse Gebiete, was ein völlig anderer Ansatz ist als den wir insbesondere hier im Rahmen von Einzelfall-Betrachtungen im Sturmforum normalerweise tun. Uns interessiert ja meist bloss der "peak convective precipitation" in unserem Chasing-Rayon bei entsprechend geiler Wetterlage - wenn das konsultierte Modell hier gut performt wird es für uns solange das Beste sein, bis ein gegenteiliger Fall eintritt, um es einmal etwas salopp zu formulieren

 Dies dank dem ennet der Grenze vom Bodensee her richtung Schwarzwald vorbeiziehenden Gewitterchen.
Dies dank dem ennet der Grenze vom Bodensee her richtung Schwarzwald vorbeiziehenden Gewitterchen.